

So konvertieren Sie Bilder in der Linux-Befehlszeile mit OCR -

Die Premium-Optimal Character Recognition (OCR)-Software war in der Vergangenheit vielleicht teuer, aber sie ist jetzt kostenlos über die Befehlszeile Ihres Linux-Terminals verfügbar! Dieser Artikel hilft Ihnen bei der Einrichtung und den ersten Schritten mit OCR.
Zusammenfassung
Was ist OCR?
Die Abkürzung OCR steht für Optimale Zeichenerkennung: eine Software und ein System, mit dem ein Computer den Text in den Bildern lesen kann. Stellen Sie sich vor, Sie machen ein Foto Ihrer Lieblingspassage aus einem Herr der Ringe-Buch.
Sie möchten es an anderer Stelle zitieren, haben aber nur ein Foto. OCR-Software kann Ihnen helfen, indem sie dieses Foto / Bild analysiert und den gesamten Text darin findet.
Die OCR-Software analysiert dann für jeden entdeckten Buchstaben die im Bild zu sehenden grafischen Punkte und übersetzt / wandelt diese in echten Text um, den ein Computer beispielsweise in einem Textverarbeitungsprogramm verwenden kann.
Obwohl es viele OCR-Software gibt, einige kostenpflichtig und einige kostenlos, sind nicht alle von der gleichen Qualität. Einige Pakete liefern qualitativ schlechtere Ergebnisse, andere richten sich eng an den auf dem Foto oder Bild sichtbaren Text aus.
Im Allgemeinen funktionieren Standardbücher (oder Ausdrucke von Internet-Webseiten) gut und sollten in allen Fällen zu angemessenen Qualitätsergebnissen führen, da die Schriftarten gerade und gleichmäßig und in einem einzigen Winkel sind, vorausgesetzt, das Foto oder die Originaldigitalisierung ist angemessen. Qualität.
Es ist auch gut zu bedenken, dass selbst fortgeschrittene Software mit schlechter Qualität oder verschwommenen Bildern zu kämpfen haben und die meisten Pakete mit verschiedenen Handschriftstilen usw. zu kämpfen haben. Andere Herausforderungen können mit Bildern oder Fotos gemischter Text oder eine andere Richtung (zB links - Text rechts, von oben nach unten oder geneigt) auf derselben Seite sein.
Dies macht die Auswahl und möglicherweise die Bezahlung eines OCR-Pakets zu einem möglicherweise langwierigen Prozess, insbesondere wenn Sie jedes Paket testen und bewerten möchten.
Für diejenigen, die Linux verwenden, gibt es eine großartige Alternative. Kostenlose Premium-OCR-Software basierend auf LSTM Neural Net mit Unicode (UTF-8)-Unterstützung, die standardmäßig über 100 Sprachen erkennen kann. Es unterstützt auch viele Ausgabeformate wie HTML, PDF und Nur-Text.
Unverzüglich; Willkommen bei Tesseract-OCR!
Installation OCR-Tesseract
Installieren OCR-Tesseract Führen Sie auf Ihrer Debian / Apt-basierten Linux-Distribution (wie Ubuntu und Mint) Folgendes aus:
sudo apt install tesseract-ocr libtesseract-dev tesseract-ocr-eng
Installieren OCR-Tesseract Führen Sie auf RHEL und Centos Folgendes aus:
sudo yum install epel-releasesudo yum install tesseract-devel leptonica-devel
Installieren OCR-Tesseract Führen Sie auf Fedora Folgendes aus:
sudo yum install tesseract-devel leptonica-devel
Installieren OCR-Tesseract Führen Sie unter OSX Folgendes aus:
brew install tesseract
Lassen Sie uns OCR!
Wir verwenden ein einfaches Bild, das den folgenden Text enthält:

Um dieses Bild zu konvertieren, müssen Sie nur Ihre Terminal-Eingabeaufforderung öffnen, das Verzeichnis wechseln (mit dem cd your_directory_with_images Befehl) in dem Verzeichnis, das Ihre Bilder enthält (wenn Sie beispielsweise ein Bilderverzeichnis in Ihrem Home-Verzeichnis erstellt haben (~/images) kannst du einfach benutzen cd ~/images) und OCR-Dateien:
tesseract -l eng input_for_ocr.png output_from_ocr cat output_from_ocr.txt
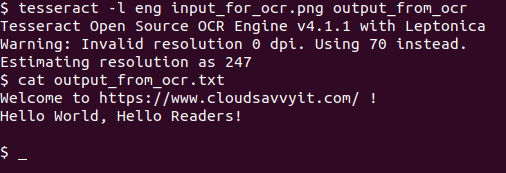
Ganz einfach und unkompliziert. Und wie wir sehen können, ist das Rendering perfekt.
Wir spezifizieren die englische Sprache mit dem -l eng Möglichkeit. Sie können das tesseract-Handbuch (man tesseract) für jeden anderen verfügbaren Sprachcode.
Wir haben auch das Eingabebild (input_for_ocr.png) sowie die Ausgabedatei output_from_ocr ohne Dateierweiterung, die standardmäßig Nur-Text verwendet .txt Format.
Wir können das Ausgabeformat auch mit einem etwas längeren Befehl in PDF ändern, der nur das Ausgabeformat am Ende angibt:
tesseract -l eng input_for_ocr.png output_from_ocr pdf

Durch Hinzufügen der pdf Suffix, das verwendete Ausgabeformat war PDF. Wenn wir die PDF-Datei öffnen (ausgabe_aus_ocr.pdf), können wir sehen, dass der Text ausgewählt und kopiert / eingefügt werden kann, wie es mit dem Wort gemacht wurde Leser! hier:

Mit anderen Worten, die PDF-Datei enthält textuelle und auswählbare Daten und keine grafischen Informationen (und daher nicht auswählbar). Großartig!
Was ist, wenn ich eine PDF-Datei mit OCR versehen möchte?
Manchmal erhalten Sie eine PDF-Datei, die - obwohl das PDF-Format den eigentlichen Text auf den Seiten unterstützt - nur Bilder mit Text enthält. Dies kann frustrierend sein, da Kopieren und Einfügen nicht verfügbar ist. Sie können diese Seiten mit einer kleinen Problemumgehung auch mit OCR versehen.
Sie sollten Ihre PDF-Datei zuerst in Bilder konvertieren - ein Bild pro Seite - und dann die einzelnen Seiten mit OCR in Text konvertieren. Etwas mehr Arbeit, aber immer noch eine beträchtliche Zeitersparnis beim manuellen erneuten Eingeben von Text.
Für einfache Schritte zum Konvertieren von PDF in Bilder oder sogar zum Skripten und Automatisieren der Konvertierung mehrerer PDF-Dateien können Sie unseren Artikel PDF in Bilder von der Linux-Befehlszeile konvertieren lesen!
Pack
In diesem Artikel haben wir uns mit Tesseract beschäftigt, der kostenlosen Premium-OCR-Engine für die Befehlszeile für Linux. Wir haben gesehen, wie wir Bilder mit einem einfachen Befehl ganz einfach in Text umwandeln können.
Wir haben uns auch die Konvertierung von Bildern in textbasierte PDFs angesehen und einen Artikel zurückgegeben, in dem Sie Informationen darüber finden, wie Sie bildbasierte PDFs in Bilder vorkonvertieren, damit sie dann mit der hier gezeigten OCR-Methode in Text umgewandelt werden können.
Freude haben!