

8 fonctionnalités C # impressionnantes à connaître –

C # et .NET ont tous deux été en développement actif constant au cours des deux dernières décennies; chaque année, la langue reçoit un ensemble de nouvelles fonctionnalités utiles. Nous discuterons de certains de nos favoris que nous pensons que les débutants devraient connaître.
Sommaire
Types de référence nulles
C # a eu nullable valeur types pendant un certain temps, comme » int? « Qui peut contenir un int ou la valeur de null, par opposition à un traditionnel int qui aurait toujours une valeur par défaut de zéro. Celles-ci sont utiles pour beaucoup de choses, y compris les classes destinées à la désérialisation JSON, où tous les champs peuvent ne pas être présents.
Cependant, les types de référence ont toujours pu se voir attribuer un null value, alors quel est l’intérêt de cette nouvelle fonctionnalité de C # 8.0?
Les types de référence Nullable appliquent essentiellement une distinction entre les variables de référence qui peuvent devenir nulles et les variables de référence qui ne le peuvent pas. C’est une fonctionnalité de rupture qui laissera probablement votre base de code avec de nombreux avertissements, c’est donc quelque chose que vous devez activer manuellement. Une fois qu’il est activé, le compilateur commence à faire la différence entre:
string?, qui peut être null et conserve le comportement «par défaut» des versions antérieures, etstring, lequel ne peux pas être nul. Il ne peut jamais être nul, car il doit recevoir une valeur par défaut et ne peut jamais être défini sur null.
Cela a beaucoup d’effets intéressants, mais le plus important est une focalisation implicite sur null gestion de la valeur au niveau de la langue. Par exemple, le compilateur vous crie dessus si vous essayez de renvoyer une valeur nulle pour une fonction qui renvoie une valeur non Nullable. Il vous criera également dessus si vous essayez de transmettre une valeur éventuellement nulle à une fonction qui ne l’attend pas.
Bien que cela puisse sembler restrictif, tout comme la saisie statique, cela conduit à un code meilleur et plus utilisable à la fin. Nous vous recommandons vivement de l’activer pour la plupart des projets, et vous pouvez lire notre guide complet sur eux pour en savoir plus.
Pour l’activer, vous devrez modifier votre fichier de projet. Dans Visual Studio, faites un clic droit sur votre projet et cliquez sur « Modifier le fichier de projet ». Puis activez-le avec la directive suivante:
<Nullable>enable</Nullable>
Si vous utilisez le format de projet hérité, vous devrez peut-être le remplacer manuellement par une directive en haut de chaque fichier:
#nullable enable
Opérateurs de coalescence Null-conditionnels et Null
Plutôt que d’avoir à vérifier if(something == null), C # a un raccourci génial avec des opérateurs d’accès aux membres conditionnels null. Fondamentalement, plutôt que d’utiliser un point pour accéder à quelque chose qui peut être nul, vous pouvez utiliser un point d’interrogation et un point, qui effectueront automatiquement la vérification de la valeur nulle.
Vous pouvez également les utiliser pour appeler des méthodes sur des objets null ou accéder aux index sur des tableaux null. Si l’objet finit par être nul, il ne fait simplement rien et renvoie une valeur nulle.
reference?.field reference?.method(); reference?[N]
Notez que le dernier n’empêche pas une IndexOutOfRangeException – il accède simplement au Nième élément d’une liste éventuellement nulle.
Cependant, vous devrez peut-être travailler avec les valeurs nulles renvoyées par cette expression et pour faciliter cela, C # a des opérateurs de fusion null. Ceux-ci peuvent être utilisés pour attribuer une valeur alternative dans le cas où une expression (n’importe quelle expression) renvoie une valeur nulle. Ce sont essentiellement des valeurs de sauvegarde. Vous pouvez les spécifier avec des points d’interrogation doubles:
string value = GetValue() ?? "Backup"
Il y a aussi le ??= opérateur, qui fonctionne comme || en ce qu’il n’évaluera pas la valeur de sauvegarde si la première valeur renvoie un résultat correct.
Tuples
Vous avez toujours voulu renvoyer plusieurs valeurs d’une méthode? Avec les tuples, vous pouvez, et le C # moderne a un excellent support de langage pour eux depuis C # 7.0. Renvoyez simplement deux valeurs entre parenthèses et séparées par des virgules, et vous pouvez accéder aux éléments individuels qu’elles contiennent.

Bien que ce ne soit pas obligatoire, il est courant de donner ces noms, tels que (float X, float Y, float Z), plutôt que d’y accéder par des numéros d’article.
Vous pouvez également utiliser la déconstruction de tuple pour dissocier un tuple en plusieurs variables de composant.

C’est en fait très utile pour les constructeurs simples, où vous devez définir quelques champs égaux aux arguments d’entrée. L’utilisation de la déconstruction de tuple accomplit cela assez proprement:

Surcharge du constructeur avec: this ()
Les constructeurs, comme toute autre méthode, peuvent être surchargés d’opérateurs pour prendre en charge de nombreuses combinaisons de paramètres. Cependant, comme les constructeurs sont couramment utilisés pour initialiser de nombreux champs, cela peut entraîner une duplication de code.
Une solution rapide et sale consisterait à partager une méthode «d’initialisation de la classe» qui est appelée à partir de toutes les méthodes de constructeur surchargées, mais si vous avez activé les types de référence Nullable, vous obtiendrez des avertissements de nullabilité pour les champs non Nullable qui sont en train d’être définis, car le compilateur n’est pas assez intelligent pour comprendre l’initialisation dans les appels de fonction impurs.

Mais il y a une solution à cela, et c’est un peu bizarre. Ça vient de héritage du constructeur, qui est une autre fonctionnalité géniale qui vous permet d’étendre le constructeur de la classe de base. Il utilise la même syntaxe d’héritage, un signe deux-points, suivi de base (parameters). Cela appellera automatiquement le constructeur de base (avant le nouveau). Notez que vous devez toujours mettre les paramètres du constructeur de base dans la définition de méthode.

La partie cool est que vous n’avez pas besoin d’utiliser base; vous pouvez faire exactement la même chose avec : this (), qui appellera un constructeur dans la classe elle-même. Vous pouvez l’utiliser pour spécifier des paramètres supplémentaires sans copier le code d’initialisation.

Vous devrez évidemment déclarer les champs optionnels comme nullables, car ils le sont car le constructeur de base ne les prend pas en charge. Mais c’est par conception ici; dans cet exemple, le prénom et le nom de la personne doivent être définis, mais l’e-mail peut ou non l’être, ce qui le rend approprié pour un type Nullable.
Constructeurs statiques
Les constructeurs sont couramment utilisés pour créer des instances de classes en utilisant le new mot-clé. Dans le constructeur, vous pouvez configurer les champs requis pour initialiser la classe.
Mais qu’en est-il des classes statiques? Eh bien, ils peuvent également utiliser des constructeurs. En fait, les classes régulières peuvent utiliser des constructeurs statiques pour configurer leurs propriétés statiques.

Cependant, ceux-ci ne s’exécutent pas exactement au démarrage. Bien que l’exemple ci-dessus semble correct, le réglage startupTime dans un constructeur statique, ce n’est pas garanti à l’exécution car C #, et le MSIL sur lequel il s’exécute, est un langage compilé Just-In-Time.
La compilation JIT ne se produit, enfin, juste à temps, exactement au moment où la classe est nécessaire. Cela signifie que la classe restera assise dans son coin de l’assemblage, collectant la poussière jusqu’à ce que l’un de ses champs ou méthodes soit nécessaire. Une fois que c’est nécessaire, le runtime .NET le dépoussiérera, le compilera et n’appellera ensuite le constructeur statique.
Cependant, le constructeur statique s’exécute toujours avant n’importe quoi, avant même que les champs statiques ne soient configurés et avant que quoi que ce soit ne puisse être référencé. Ils sont toujours très utiles lorsque vous en avez besoin. Vous pouvez également appeler une méthode d’initialisation à partir de la routine de démarrage de votre application si vous devez exécuter quelque chose dans l’ordre chronologique.
Paramètres de type générique
Vous en avez certainement déjà rencontré, même si vous n’en avez peut-être pas écrit vous-même. Les paramètres de type générique vous permettent d’écrire des fonctions qui sont indépendantes du type et ne se soucient pas du type qui leur est passé. Le principal exemple en est les collections; une List<string> et un List<int> utilise le même code, mais reçoit un paramètre de type générique différent.
Les génériques sont assez faciles à utiliser vous-même. Ajoutez simplement un nom pour la variable de type entre crochets dans la définition de classe ou de méthode. Il est courant d’utiliser T, ou du moins des noms commençant par T. Par exemple, un dictionnaire peut avoir TKey et TValue, deux types différents.
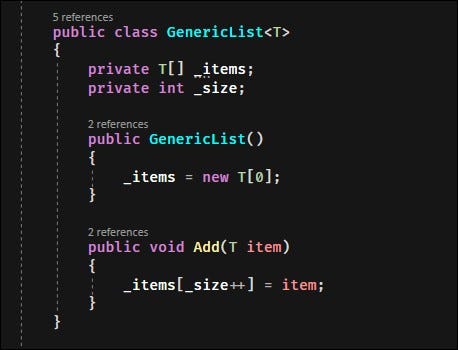
Les types génériques créent plusieurs «types» différents de la classe générique. Cela signifie que les champs statiques seront séparés en fonction du type de classe, donc List<string> ne partage aucune donnée avec List<int>.
Pour cette raison, vous devez lui transmettre un paramètre de type si vous souhaitez référencer directement le nom de la classe. Cela peut être un problème dans certains cas, donc, si vous devez prendre en charge plusieurs types, vous pouvez effectuer un cast vers et depuis object en utilisant une technique appelée boxe.
Délégués
Les délégués sont un moyen de regrouper les méthodes en variables. Ceci est utile pour l’injection de dépendances, qui est un nom trop sophistiqué pour un concept simple – les classes flexibles devraient obtenir des valeurs, appelées dépendances, de leurs variables de constructeur, permettant à l’utilisateur de cette classe de spécifier les dépendances à volonté.
Les délégués vous permettent de le faire avec des fonctions. Vous pouvez demander à la classe de prendre n’importe quel type d’action, et elle ne se soucie pas de l’implémentation. Ceux-ci sont toujours typés statiquement – vous devrez définir les paramètres d’entrée et de sortie comme vous le feriez avec n’importe quelle fonction, sauf le marquer avec «délégué» et ne pas écrire de corps.

Vous pouvez ensuite affecter une fonction à cette variable, puis utiliser le variable pour appeler la fonction. Vous pouvez le faire directement comme indiqué, ou vous pouvez utiliser myDelegate.Invoke(), qui fait la même chose mais plus verbeux.

Vous pouvez en savoir plus sur les délégués dans notre guide d’utilisation.
Indexeurs
Les classes en C # utilisent des champs pour stocker des données et des propriétés pour exposer ces données à d’autres classes. Les propriétés ne sont en réalité qu’une méthode exposant un champ afin que vous puissiez y accéder en faisant class.property.
Vous pouvez faire la même chose pour l’indexation, par exemple class[index]. Cela peut être utilisé pour créer un comportement d’indexation personnalisé. Par exemple, vous pouvez créer une liste 2D à partir d’un 1D List<T> en créant un indexeur personnalisé qui renvoie une valeur basée sur les arguments d’entrée.
